
Using Software Load Balancing in High Availability (HA) for OpenStack Cloud API Services
In two previous posts, my colleagues Oleg Gelbukh and Piotr Siwczak covered most of the ground on making OpenStack highly available (HA). If you haven't read those posts yet, it's a good time to do so:
In this post, I'll offer some direct practical advice on completing the puzzle: enabling HA load balancing for OpenStack API services.
All of these services are stateless, so putting a highly available load balancer on top of a few instances of the services is enough for most purposes. Here I'll consider one option: HAProxy + Keepalived; however, other options are possible (e.g., HAProxy + Pacemaker + Corosync, or a hardware load balancer).
Which services?
As discussed in previous posts, we're talking about OpenStack REST API services: nova-api, keystone-api, and glance-api.
Types of failures
Several kinds of outages can happen in a distributed system like OpenStack. Here are the major ones:
- Service instance failure: A particular instance of a service crashes, but the other processes on the same machine function normally.
- Machine failure: A whole machine becomes unusable, perhaps due to a power outage or network failure.
- Network partition: Several network segments become unable to talk to each other (e.g., a higher-level switch malfunctions) but can talk to everybody within their segment. This poses a huge problem for any stateful services and is the root cause of the sheer complexity of different consistency models for distributed data stores (how to synchronize the changes made on different partitions when connectivity is restored). However, for stateless services, it's simply equivalent to machines on different ends of the partition becoming unavailable to each other.
There are also more complex kinds of failures, such as when a service hangs or starts giving the wrong answers due to hardware failure or other problems.
Some of these failures can be mitigated by monitoring at the application level; for example, by checking that the service gives an expected answer to a sample request, and restarting the service otherwise. Some failures, alas, cannot.
NOTE: In this post, I'm only covering service/machine crashes.
Surviving service failures
Suppose we have an external load balancer that we assume to be always available. Then we spawn several instances of the necessary services and balance them.
Whenever a request arrives, the balancer will attempt to proxy the request for us and connect to one of the backend servers. If a connection cannot be established, the load balancer will transparently try another instance.
Note that this provides no protection against failure of a service in the middle of executing a request. More on this later.
Surviving load balancer failures
So what if the load balancer itself fails? As a load balancer is almost stateless (except for stickiness, which we can ignore in OpenStack), we just need to put a virtual IP address on top of a bunch of load balancers (two is often enough). This can be done using Keepalived or other similar software.
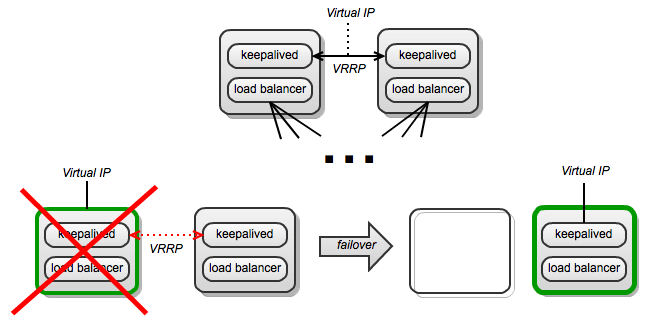
This construction makes the virtual IP address refer to "whichever balancer is available." The details, in the case of Keepalived, are implemented using the VRRP protocol. When a node owning the virtual IP dies, the other Keepalived will notice and assign the IP address to itself.
What if the loadbalancer software crashes but the node survives (very unlikely but possible)? For that, Keepalived has "check scripts"—just configure Keepalived to use a script that checks if the load balancer is running, and whenever it's not, Keepalived considers the node unusable and moves the virtual IP to a usable node.
What if Keepalived crashes? The other Keepalived will think the whole node died and claim the virtual IP.
NOTE: VRRP, and thus Keepalived, leaves a short window of unavailability during failover.
Transitional failure effects
There are at least three levels of fault tolerance with very different guarantees and different implementation complexity:
- Level 1: Failure of a component does not lead to permanent disruption of service.
- Level 2: Failure of a component does not lead to failure of new requests.
- Level 3: Failure of a component does not lead to failure of any requests (new orcurrently executing).
At level 1, there may be a window of unavailability (the shorter, the better), e.g., until we detect that a particular server became unusable and tell the client to use another one instead.
At level 2, no new requests are denied, though currently executing requests may fail. This is harder: We must be able to direct any request to a currently available instance, which requires the infrastructure to proxy, and not just redirect the connections. Here we assume that if a connection can be established, the server will not die while serving the request—this is equivalent to assuming that requests take zero time, otherwise it's equivalent to level 3.
At level 3, the failure recovery happens transparently even to someone who's executing a long request with a server that now failed.
Level 3 is usually impossible to implement fully at an infrastructure level because it requires 1) buffering requests and responses and 2) understanding how to safely retry each type of request.
For example: What if a large file upload or download fails? Should the infrastructure buffer the whole file and re-upload/re-serve it? What if a call with side effects failed, having perhaps performed half of them—is it safe to retry it?
Implementing this level of fault tolerance requires a layer of application-specific retry logic on the client and special support for avoiding duplicate side effects on the server.
The setup I'm discussing in this post gives level 2 protection against service failures and level 1 for balancer failures.
NOTE: Previous posts on MySQL and RabbitMQ HA introduced level 3 tolerance to their failures as there is retry logic in place, at least if you use the proper patches mentioned in the posts.
Software topology
As mentioned, we'll use the following set of software:
- the services themselves;
- HAProxy for making the services HA; and
- Keepalived for making HAProxy HA.
We'll have two types of nodes: a service node and an endpoint node. A service node hosts services, while an endpoint node hosts HAProxy and Keepalived. A node can also play both roles at the same time.
Wiring of services to each other
Services must address each other by the virtual IP in order to take advantage of each other's high availability.
Also, if higher than level 1 or 2 fault tolerance is needed, application-specific retry logic should be introduced. As far as I know, nobody currently retries internal calls in OpenStack (just calls to Keystone), and it seems that in most cases it's enough to retry external ones.
Getting hands-on
Enough theory, let's build the thing.
Suppose we have two machines, from which we want to make an HA OpenStack controller pair, installing both the API services and Keepalived + HAProxy.
Suppose machine 1 has address 192.168.56.200, machine 2 has address 192.168.56.201, and we want the services to be accessible through virtual IP 192.168.56.210. And suppose all these IPs are on eth1.
This is how everything is wired (it's similar for other services; HAProxy and Keepalived are shared,of course).
Installing necessary packages
I'm assuming that you're on Ubuntu, in which case you should type:
$ sudo apt-get install haproxy keepalived
Configuration of haproxy
This configuration is identical on both nodes and resides in /etc/haproxy/haproxy.cfg.
$ cat /etc/haproxy/haproxy.cfg
global
chroot /var/lib/haproxy
daemon
group haproxy
log 192.168.56.200 local0
maxconn 4000
pidfile /var/run/haproxy.pid
stats socket /var/lib/haproxy/stats
user haproxy
defaults
log global
maxconn 8000
mode http
option redispatch
retries 3
stats enable
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
listen keystone-1 192.168.56.210:5000
balance roundrobin
option tcplog
server controller-1 192.168.56.200:5000 check
server controller-2 192.168.56.201:5000 check
listen keystone-2 192.168.56.210:35357
balance roundrobin
option tcplog
server controller-1 192.168.56.200:35357 check
server controller-2 192.168.56.201:35357 check
listen nova-api-1 192.168.56.210:8773
balance roundrobin
option tcplog
server controller-1 192.168.56.200:8773 check
server controller-2 192.168.56.201:8773 check
listen nova-api-2 192.168.56.210:8774
balance roundrobin
option tcplog
server controller-1 192.168.56.200:8774 check
server controller-2 192.168.56.201:8774 check
listen nova-api-3 192.168.56.210:8775
balance roundrobin
option tcplog
server controller-1 192.168.56.200:8775 check
server controller-2 192.168.56.201:8775 check
listen nova-api-4 192.168.56.210:8776
balance roundrobin
option tcplog
server controller-1 192.168.56.200:8776 check
server controller-2 192.168.56.201:8776 check
listen glance-api 192.168.56.210:9292
balance roundrobin
option tcplog
server controller-1 192.168.56.200:9292 check
server controller-2 192.168.56.201:9292 check
This configuration encompasses the four nova-api services (EC2, volume, compute, metadata), glance-api, and the two keystone-api services (regular and admin API). If you have something else running (e.g., swift proxy), you know what to do.
For more information, you can read a HAProxy manual.
Now restart HAProxy on both nodes:
$ sudo service haproxy restart
Configuration of Keepalived
This configuration is almost, but not quite identical on both nodes as well, and resides in /etc/keepalived/keepalived.conf.
The difference is that one node has its priority defined as 101, and the other as 100. Whichever of the available nodes has highest priority at any given moment, wins (that is, claims the virtual IP).
$ cat /etc/keepalived/keepalived.conf
global_defs {
router_id controller-1
}
vrrp_instance 42 {
virtual_router_id 42
# for electing MASTER, highest priority wins.
priority 101
state MASTER
interface eth1
virtual_ipaddress {
192.168.56.210
}
}
For more information, you can read a Keepalived manual.
And now let us check that Keepalived + HAProxy work by poking glance:
$ telnet 192.168.56.210 9292
Trying 192.168.56.210...
Connected to 192.168.56.210.
Escape character is '^]'.
^]
telnet> quit
Connection closed.
Also, we can see that just one of the controllers—the one with higher "priority"—claimed the virtual IP:
openstack@controller-1:~$ ip addr show dev eth1
2: eth1: mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 08:00:27:9d:c4:b0 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.200/24 brd 192.168.56.255 scope global eth1
inet 192.168.56.210/32 scope global eth1
inet6 fe80::a00:27ff:fe9d:c4b0/64 scope link
valid_lft forever preferred_lft forever
openstack@controller-2:~$ ip addr show dev eth1
2: eth1: mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 08:00:27:bd:7f:14 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.201/24 brd 192.168.56.255 scope global eth1
inet6 fe80::a00:27ff:febd:7f14/64 scope link
valid_lft forever preferred_lft forever
Configuration of OpenStack services
Now for the service wiring. We need two things:
1) to listen on the proper local IP address and
2) address others by the virtual IP address.
Nova
openstack@controller-1:~$ cat /etc/nova/nova.conf
--metadata_listen=192.168.56.200
--glance_api_servers=192.168.56.210:9292
--osapi_volume_listen=192.168.56.200
--ec2_listen=192.168.56.200
--sql_connection=mysql://nova:nova@192.168.56.210/nova
--osapi_compute_listen=192.168.56.200
--novncproxy_host=192.168.56.210
...
openstack@controller-1~$ cat /etc/nova/api-paste.ini
...
[filter:authtoken]
auth_host = 192.168.56.210
auth_uri = http://192.168.56.210:35357/v2.0
...
Keystone
openstack@controller-1~$ cat /etc/keystone/keystone.conf
[DEFAULT]
bind_host = 192.168.56.200
...
[sql]
connection = mysql://keystone_admin:nova@192.168.56.210/keystone
...
Glance
openstack@controller-1:~$ cat /etc/glance/glance-scrubber.conf
[DEFAULT]
registry_host = 192.168.56.210
...
openstack@controller-1:~$ cat /etc/glance/glance-api-paste.ini
...
[filter:authtoken]
auth_host = 192.168.56.210
auth_uri = http://192.168.56.210:5000/
...
openstack@controller-1:~$ cat /etc/glance/glance-api.conf
[DEFAULT]
registry_host = 192.168.56.210
bind_host = 192.168.56.200
...
openstack@controller-1:~$ cat /etc/glance/glance-api-paste.ini
...
[filter:authtoken]
auth_host = 192.168.56.200
auth_uri = http://192.168.56.200:5000/
...
openstack@controller-1:~$ cat /etc/glance/glance-cache.conf
[DEFAULT]
registry_host = 192.168.56.210
auth_url = http://192.168.56.210:5000/
...
openstack@controller-1:~$ cat /etc/glance/glance-registry.conf
[DEFAULT]
bind_host = 192.168.56.200
sql_connection = mysql://glance:nova@192.168.56.210/glance
...
openstack@controller-1:~$ cat /etc/glance/glance-registry-paste.ini
[filter:authtoken]
auth_host = 192.168.56.210
auth_uri = http://192.168.56.210:5000/
...
Openrc file
openstack@controller-1:~$ cat /root/openrc
export OS_AUTH_URL="http://192.168.56.210:5000/v2.0/"
export SERVICE_ENDPOINT=http://192.168.56.210:35357/v2.0/
...
Now, assuming you have OpenStack running, you can try doing something with your HA setup.
openstack@controller-1:~$ nova image-list
+--------------------------------------+--------+--------+--------+
| ID | Name | Status | Server |
+--------------------------------------+--------+--------+--------+
| ef0dfac5-5977-405c-8e62-595af17aa01d | cirros | ACTIVE | |
+--------------------------------------+--------+--------+--------+
Conclusion
So, we can deploy an almost1 fully HA OpenStack by combining the contents of this post and the two previous posts (OpenStack HA in general and MySQL and RabbitMQ HA).
That was easy! You can thank the modular design of OpenStack, but perhaps the most credit should be given to the fact that components are wired via asynchronous messaging (RabbitMQ), whose main purpose is helping to build fault-tolerant systems.
1 Why almost? Because we have a short unavailability window during failover of a load balancer, and because currently executing requests will break during failover. This can be mitigated by retrying requests (client-side and by developing a patch for Nova to retry internal Keystone requests), but it gets a lot more difficult if the requests can have side effects.






