
Improving Trove Architecture Design with Conductor Service
This is the second in a series of blog posts discussing OpenStack Trove. Trove is OpenStack’s Database as a Service (DBaaS) project, whose intent is to provide all of the capabilities of a relational database without the hassle of having to handle complex administrative tasks. Here we explain the current Trove design issues and our decision to create a conductor service for Trove.
The current Trove architecture design has one issue--the guest service inside a provisioned VM requires Trove back-end connectivity to update its status from BUILD to ACTIVE. Since Trove and OpenStack could differ, it’s possible that the guest service would not be able to communicate with the back-end. We present a solution that’s already well-known to OpenStack services--MQ. That’s why we designed and created a conductor service for Trove called Trove-conductor.
The Trove Conductor is a service that runs on the host and is responsible for receiving messages from guest instances to update the information on the host, for example, an instance status or current backup status. When you have a Trove Conductor, guest instances do not require a direct connection to the host's database. The conductor listens for RPC messages through the message bus and performs the corresponding operation.
The conductor is like the guestagent in that it is a service that listens to a RabbitMQ topic, with the difference that the conductor lives on the host and not the guest. The MQ service has several topics, and each topic is a queue of messages. Guest agents communicate with the conductor by putting messages on the topic defined in the conductor configuration file as the conductor_queue. The conductor reads a topic named trove-conductor (conductor_queue=trove-conductor), and that’s the default topic.
The service start script (Trove/bin/trove-conductor) works as follows:
It runs as RpcService configured by
Trove/etc/trove/trove-conductor.conf.sample, which definestrove.conductor.manager.Manageras the manager. This is the entry point for requests arriving into the queue.The script helps deployer understand which parameters should be listed in the real trove-conductor.conf. Note that thetrove-conductor.conf.samplecontains a set of paramerets that are required to start theconductor service.Just as in the case of the guestagent, requests are pushed asynchronously to the MQ from another component using
_cast, generally in the form of{"method": "<method_name>", "args": {<arguments>}}. These arecall()andcast()methods, which take the name of, and map the parameters for, the method that will be executed.trove/conductor/manager.pydoes the actual database update--The "heartbeat" method updates the status of an instance. It is a method that checks if the database service is running and then sends the status (ACTIVE,FAILED,ERROR, orSHUTDOWN) to the conductor in response to the executed method. It reports if an instance has changed fromNEW toBUILDING toACTIVE, and so on.The
update_backupmethod changes the details of a backup, including its current status, size, type, and checksum.
Conductor integration
In phase 1 of conductor integration, the guestagent service communicates with the back-end through the conductor service. The guestagent service casts specific calls, such as heartbeat and update_backup to the conductor service. Each of these tasks requires a db connection for persisting models. The schema is show in figure 1.
The benefit of such a solution is that the compute instance and the Trove backend are not connected. That means that the backend can work in another network/datacenter and that the guest service would not be able to communicate with it directly, which means that the guest can’t update its own status inside the Trove back-end. After a predefined timeout, the taskmanager service marks the instance with an ERROR status, which means that the guest is broken .
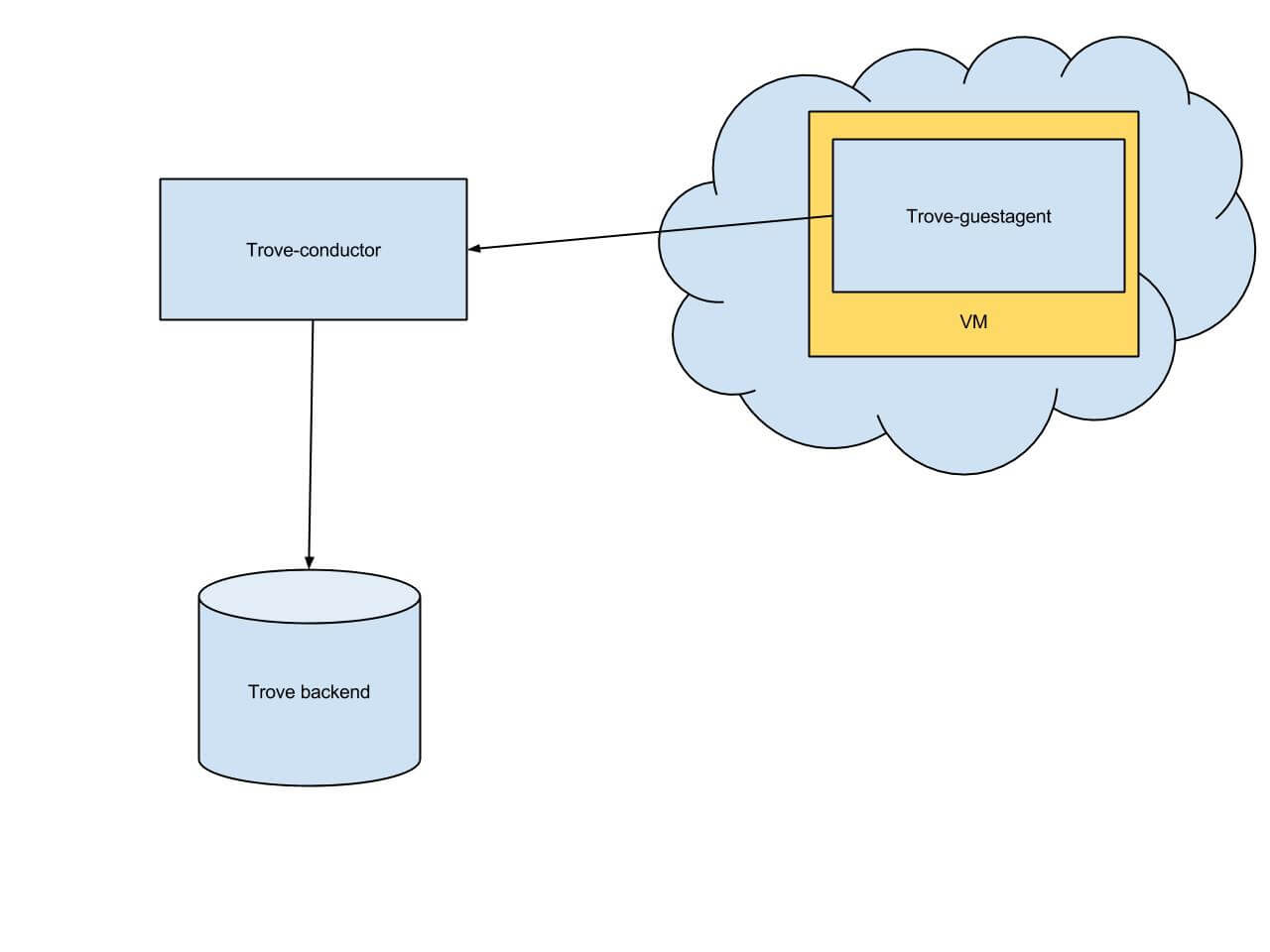
Figure 1 Phase 1 conductor usage schema
In phase 2 of conductor integration, the conductor service takes tasks from the taskmanager. The conductor becomes a single entry point for tasks requiring a db-connection for the guestagent and taskmanager services. As mentioned earlier, the conductor is a service that takes from the guest the tasks that require a db-connection. The conductor is an executor that has a direct connection to the back-end.
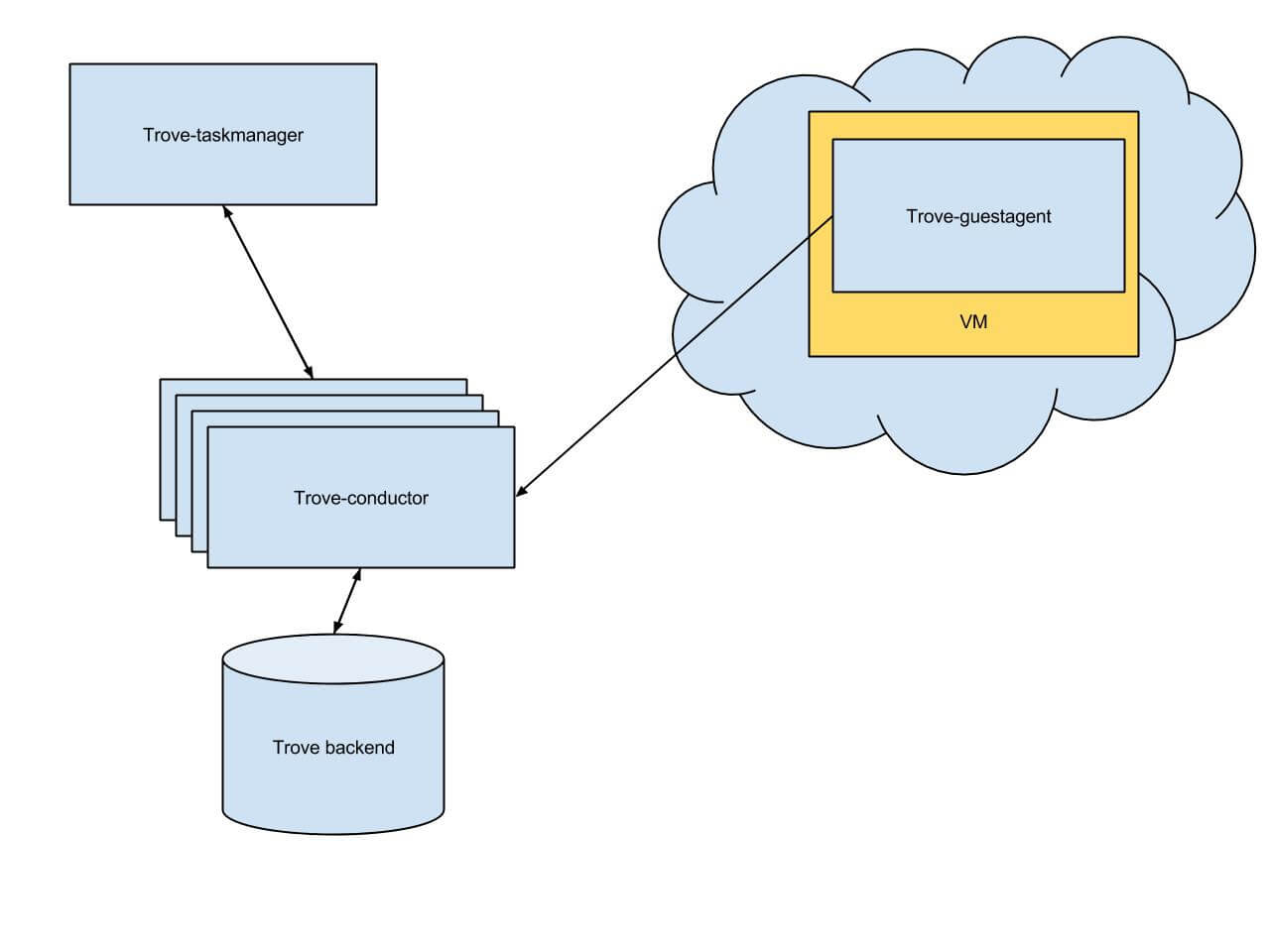
Figure 2 Phase 2 conductor usage schema
Phase 2 assumes that the deployer can launch more than one instance of the conductor service.
With the db-connection in a single place, the persistance models are now managed by two services--the trove-api and the conductor itself.
In phase 3, the conductor becomes the single entry point for any tasks that require db-connection, including the API service.
The remaining part of integration are db interactions for the trove-api service. Figure 3 shows those interactions.

Figure 3 Phase 3 conductor usage schema
After such changes, the conductor can deal with everything related to back-end--the models’ CRUD operations. Let’s take a look at the final scheme.
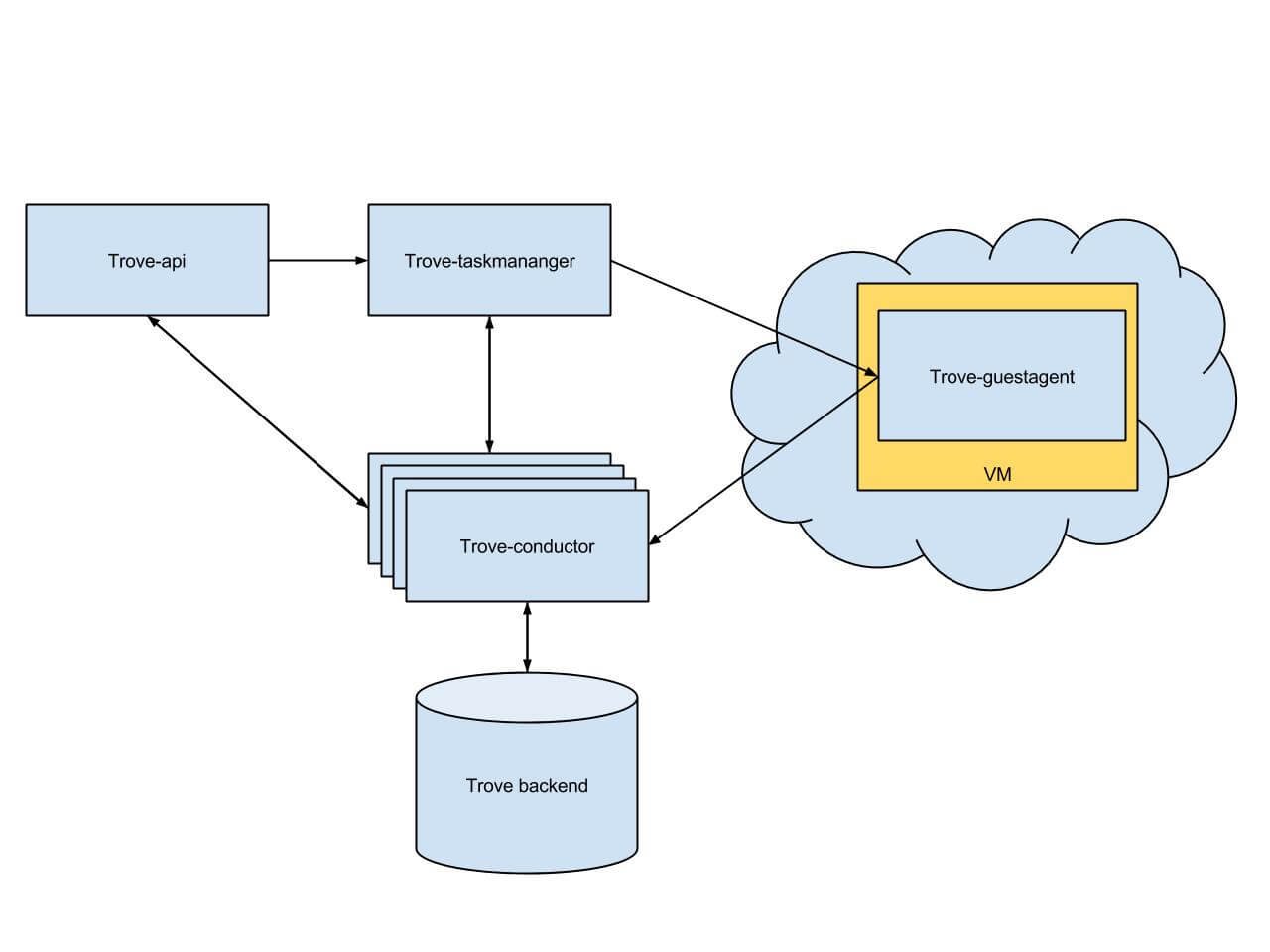
Figure 4 Final conductor usage schema
As you can see from last schema, the conductor becomes a single entry point for the models’ CRUD operations. Such an architectural design allows all Trove services to communicate with the conductor service over the MQ service (any kind of AMPQ protocol implementation). This makes for a sound decision when it comes to planning for the future.
Summary
The Trove Conductor is a service that runs on the host and is responsible for receiving messages from guest instances to update the information on the host. It breaks the connectivity with the Trove back-end, obliterating the problem of unreachable back-end host. The conductor service becomes a single entry point for any back-end required tasks.






